




What's nagging you the most when you think about logging in NodeJS? If you ask me I'm gonna say lack of of industry standards for creating trace IDs. Within this article we'll overview how we can create these trace IDs (meaning we're going to briefly examine how continuation local storage a.k.a CLS works) and dig deep into how we can utilize Proxy to make it work with ANY logger.
Why is it even a problem to have a trace ID for each request in NodeJS?
Well, on platforms that use multi-threading and spawn a new thread for each request. There's a thing called thread-local storage a.k.a. TLS, which allows keeping any arbitrary data available to anything within a thread. If you have a native API to do that it's pretty trivial to generate a random ID for each request, put it in TLS and use it in your controller or service later. So what's the deal with NodeJS? As you know, NodeJS is a single-threaded (not really true anymore as we now have workers, but that doesn't change the big picture) platform, which makes TLS obsolete. Instead of operating different threads NodeJS runs different callbacks within the same thread (there's a great series of articles on event loop in NodeJS if you're interested) and NodeJS provides us with a way to uniquely identify these callbacks and trace their relations with each other.
Back in the old days (v0.11.11) we had addAsyncListener which allowed us to track asynchronous events. Based on it Forrest Norvell built first implementation of continuation local storage a.k.a. CLS. We're not going to cover that implementation of CLS due to the fact that we, as developers, were stripped of that API in v0.12 already.
Until NodeJS 8 we had no official way of hooking up to NodeJS' async event processing. And finally NodeJS 8 granted us the power we lost via async_hooks (if you want to get a better understanding of async_hooks take a look at this article). This brings us to the modern async_hooks-based implementation of CLS - cls-hooked.
CLS overview
Here's a simplified flow of how CLS works:
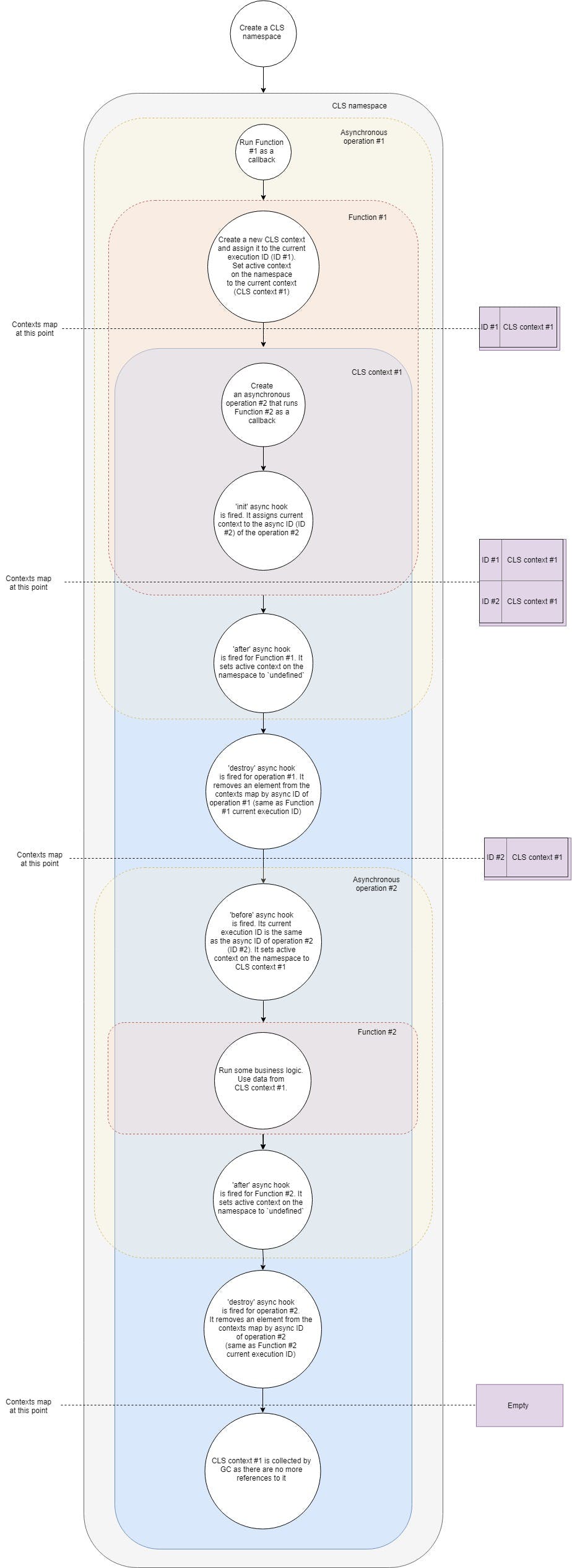
Let's break it down step-by-step:
- Say, we have a typical web server. First we have to create a CLS namespace. Once for the entire lifetime of our application.
- Second we have to configure a middleware to create a new CLS context for each request. For simplicity let's assume that this middleware is just a callback that is called upon receiving a new request.
- So when a new request arrives we call that callback function.
- Within that function we create a new CLS context (one of the ways is to use run API call).
- At this point CLS puts the new context in a map of contexts by current execution ID.
- Each CLS namespace has
activeproperty. At this stage CLS assignsactiveto the context. - Inside of the context we make a call to an asynchronous resource, say, we request some data from the database. We pass a callback to the call, which is going to run once the request to the database is completed.
- init async hook is fired for new asynchronous operation. It adds the current context to the map of contexts by async ID (consider it an identifier of the new asynchronous operation). Now in that map we two IDs pointing to the same context.
- As we have no more logic inside of our first callback it exits effectively ending our first asynchronous operation.
- after async hook is fired for the first callback. It sets active context on the namespace to
undefined(it's not always true as we may have multiple nested contexts, but for the most simple case it is true). - destroy hook is fired for the first operation. It removes the context from our map of contexts by its async ID (it's the same as current execution ID of our first callback).
- The request to the database has finished and our second callback is about to be triggered.
- At this point before async hook comes in play. Its current execution ID is the same the async ID of the second operation (database request). It sets
activeproperty of the namespace to the context found by its current execution ID. It's the context that we created before. - Now we run our second callback. Run some business logic inside. Within that function we can get any value by key from the CLS and it is going to return whatever it finds by the key in the context we created before.
- Assuming that it's the end of processing of the request our function returns.
- after async hook is fired for the second callback. It sets active context on the namespace to
undefined. destroyhook is fired for the second asynchronous operation. It removes our context from the map of contexts by its async ID leaving it absolutely empty.- As we no longer hold any references to the context object our garbage collector frees the memory associated with it.
It's a simplified version of what's going on under the hood, yet it covers all major steps. If you want to dig deeper you can take a look at the source code. It's less than 500 lines.
Generating trace IDs
So once we got an overall understanding of CLS let's think how we can utilize it for our own good. One thing we could do is create a middleware that wraps every request in a context, generates a random identifier and puts it in CLS by key traceID. Later, inside of one of our gazillion controllers and services we could get that identifier from CLS.
For express this middleware could look like this:
const cls = require('cls-hooked')
const uuidv4 = require('uuid/v4')
const clsNamespace = cls.createNamespace('app')
const clsMiddleware = (req, res, next) => {
// req and res are event emitters. We want to access CLS context inside of their event callbacks
clsNamespace.bind(req)
clsNamespace.bind(res)
const traceID = uuidv4()
clsNamespace.run(() => {
clsNamespace.set('traceID', traceID)
next()
})
}
Then in our controller we could get the trace ID generated like this:
const controller = (req, res, next) => {
const traceID = clsNamespace.get('traceID')
}
There's not so much use of this trace ID unless we add it to our logs.
Let's add it to our winston.
const { createLogger, format, transports } = require('winston')
const addTraceId = printf((info) => {
let message = info.message
const traceID = clsNamespace.get('taceID')
if (traceID) {
message = `[TraceID: ${traceID}]: ${message}`
}
return message
})
const logger = createLogger({
format: addTraceId,
transports: [new transports.Console()],
})
Well, if all loggers supported formatters in a form of functions (many of them don't do that for a good reason) this article wouldn't exist. So how would one add a trace ID to my beloved pino? Proxy to the rescue!
Combining Proxy and CLS
Proxy is an object that wraps our original object allowing us to override its behavior in certain situations. List of these situations (they are actually called traps) is limited and you can take a look at the whole set here, but we're only interested in trap get. It provides us with an ability to intercept property accessing. It means that if we have an object const a = { prop: 1 } and wrap it in a Proxy, with get trap we could return anything we want for a.prop.
So the idea is to generate a random trace ID for each request and create a child pino logger with the trace ID and put it in CLS. Then we could wrap our original logger with a Proxy, which would redirect all logging request to the child logger in CLS if found one and keep using the original logger otherwise.
In this scenario our Proxy could look like this:
const pino = require('pino')
const logger = pino()
const loggerCls = new Proxy(logger, {
get(target, property, receiver) {
// Fallback to our original logger if there is no child logger in CLS
target = clsNamespace.get('loggerCls') || target
return Reflect.get(target, property, receiver)
},
})
Our middleware would transform into something like this:
const cls = require('cls-hooked')
const uuidv4 = require('uuid/v4')
const clsMiddleware = (req, res, next) => {
// req and res are event emitters. We want to access CLS context inside of their event callbacks
clsNamespace.bind(req)
clsNamespace.bind(res)
const traceID = uuidv4()
const loggerWithTraceId = logger.child({ traceID })
clsNamespace.run(() => {
clsNamespace.set('loggerCls', loggerWithTraceId)
next()
})
}
And we could use the logger like this:
const controller = (req, res, next) => {
loggerCls.info('Long live rocknroll!')
// Logs something like
// {"level":30,"time":1551385666046,"msg":"Long live rocknroll!","pid":25,"hostname":"eb6a6c70f5c4","traceID":"9ba393f0-ec8c-4396-8092-b7e4b6f375b5","v":1}
}
cls-proxify
Based on the idea above a small library called cls-proxify was created. It has integration with express, koa and fastify out-of-the-box.
It applies not only get trap to the original object, but many others as well. So there're endless possible applications. You could proxy function calls, class construction, pretty much anything! You're limited only by your imagination!
Take a look at live demos of using it with pino and fastify, pino and express.
Hopefully, you've found something useful for your project. Feel free to communicate your feedback to me! I most certainly appreciate any criticism and questions.
Stay tuned for new articles by following me on Twitter or LinkedIn! Subscribe to my newsletter or RSS. Drop me an email if you have any questions.